什么是原型模式?

原型模式也是一种创建型设计模式,是一种通过克隆(clone)/复制的方式降低实例化开销的设计模式。通常来说,我们会克隆一个原型并稍作修改,得到一个新的实例,而不是新建实例。被复制的实例就是我们所称的“原型(prototype)”,这个原型是可定制的。原型模式多用于创建复杂的或者耗时的实例,因为这种情况下,复制一个已经存在的实例使程序运行更高效;或者创建值相等,只是命名不一样的同类数据。
让我们回忆一下工厂模式。工厂模式需要为产品创建产品基类、具体产品类、工厂基类和具体工厂类。当产品种类繁多(例如100种不同类型的敌人)时,太多的类将使系统变得异常复杂。
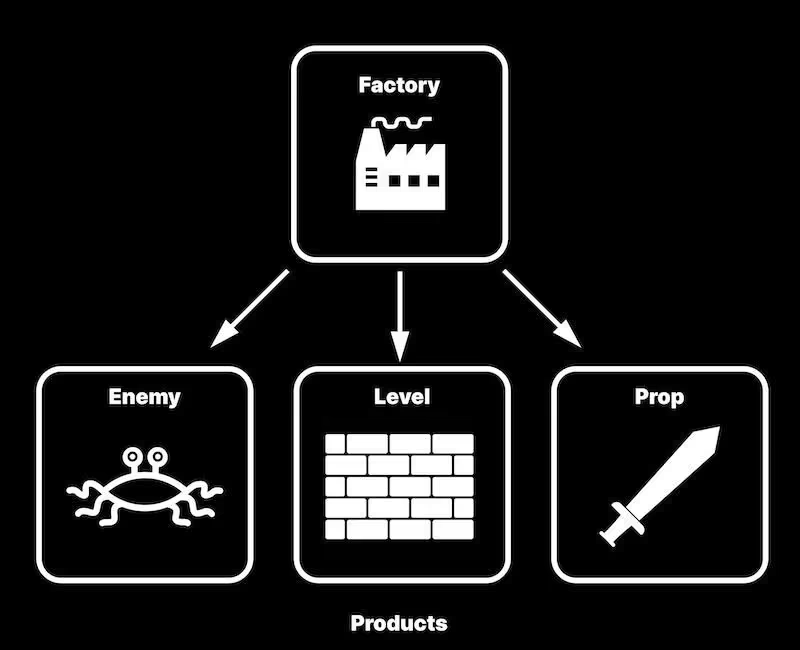
而在原型模式中,如果你有一个远程敌人,则你可以通过这个远程敌人制作出更多的远程敌人。如果你有一个近战敌人,那你就能制作出其他近战敌人。任何类型的敌人都能被看作是一个原型,用这个原型就可以复制出更多不同版本的敌人。我们不再需要复杂的抽象工厂和具体工厂类,这让类的总数减少了一半。
不过,假如需要动态添加新类型,必须为每种类型准备一个原型对象。工厂模式更通用,而原型模式在特定场景(创建大量初始状态相同的对象)中提升性能。

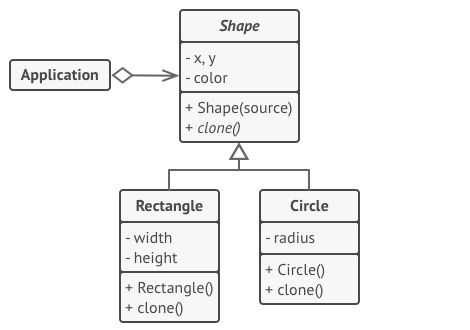
在原型模式中,存在以下三种角色:
- 产品接口
提供了clone方法 - 具体产品类
具体的产品,提供了clone方法的具体实现。该实现会返回一个与自身类型和状态相同的对象 - 生成器
产品的包装,我们可以根据产品的种类实例化不同的生成器,它可以充当中心化原型注册表(用于存储常用原型)的角色
-
优点
- 代码相对来说更加简洁。
- 可以以更低的成本创建新实例。
-
缺点
- 每个继承了产品类/接口的具体产品类都需要实现新的克隆机制。当克隆中存在循环时,这一切将会变得充满挑战。
- 每个产品都需要一个类,还是比较复杂的。采用组件模式或类型对象模式进行产品建模或许是一个更好的选择。
代码实现
1 | //怪物基类 |
关联产品的原型模式
有时我们可能会为某一具体产品创建一系列变体,例如以撒的关底boss萌死戳存在“炸弹”、“暴怒”、“精神错乱”等变种:

实现这种生成器该怎么做?我们可能很容易会想到将萌死戳的产品类抽象成接口,再实现具体类型的萌死戳产品类。在实际开发中,敌人的配置信息会被存放在配置文件(例如JSON)中,比如:
1 | { |
采用配置文件阅读起来非常直观,但很明显其中包含了一些重复数据,这会导致包体过大,在注重优化的当下这是开发者需要避免的。我们可以给对象声明一个“prototype”属性指定原型(例如初始版本的monstro),如果访问的任何属性不在此对象内部,那么会去它的原型对象里面查找。经过改写,上述配置文件可以简化为:
1 | { |
深拷贝与浅拷贝
- 深拷贝(deep copy)
在复制引用类型成员变量时,为引用类型的数据成员创建一个独立的内存空间来复制真实的内容。如果一个对象改变了这个地址,不会影响到另一个对象。

- 浅拷贝(shallow copy)
浅拷贝是对象的按位拷贝,它用原始对象属性值的精确拷贝创建一个新对象。如果属性是基本类型,则复制基本类型的值;如果属性是内存地址(引用类型),那么副本就是内存地址。
因此,如果一个对象改变了这个地址,就会影响到另一个对象。也就是说,默认的复制构造函数只是对象的浅拷贝(逐个复制成员),也就是说,只复制对象空间,而不复制资源。

应用场景
- 浅拷贝更快,消耗更低。如果对象只有字段的话很合适
- 深拷贝更慢,但是是完全独立的。如果对象有复杂引用的话很合适
参考资料
[美] Robert Nystrom 尼斯卓姆. 游戏编程模式 (游戏设计与开发). 人民邮电出版社.
https://refactoringguru.cn/design-patterns/prototype
https://gwb.tencent.com/community/detail/128274